
One of the things that set humans apart from others is their ability to learn something new over a short time. A nine-month-old baby, for instance, learns that she can bring a toy closer to her by pulling a blanket where it rests. She uses the same technique for weeks then quickly realizes that the same thing happens when she pulls tablecloths, pillows, handkerchiefs, books, and other materials. This experiment is just one of the many that researchers perform to gauge how children learn.
Scientists have also been looking into training machines to learn as humans do—that is, by experience, example, and data analysis, and that is machine learning (ML) in a nutshell. The nine-month-old baby, in the first example, learned through experience. In the same way, the goal of ML is for machines to gain the ability to learn from experience without human intervention via direct programming.
Another simple way to put it is this: ML is the scientific study that looks into training computers to program themselves. Traditionally, software developers create programs that tell computers what to do to come up with desired outputs. With ML, data scientists teach machines to automatically process data, learn from them, and produce the programs that let them generate the desired outputs.
How does Machine Learning differ from Artificial Intelligence?
ML and artificial intelligence (AI) are two computer science terms often thrown about together. People may even confuse them to mean the same thing, which is not correct. So, before we proceed, let us first distinguish between the two.
AI refers to the bigger idea of teaching machines to think and behave as humans do. In contrast, ML is a subset of AI that focuses on training machines to learn from experience. The diagram below shows the relationship between AI and ML.
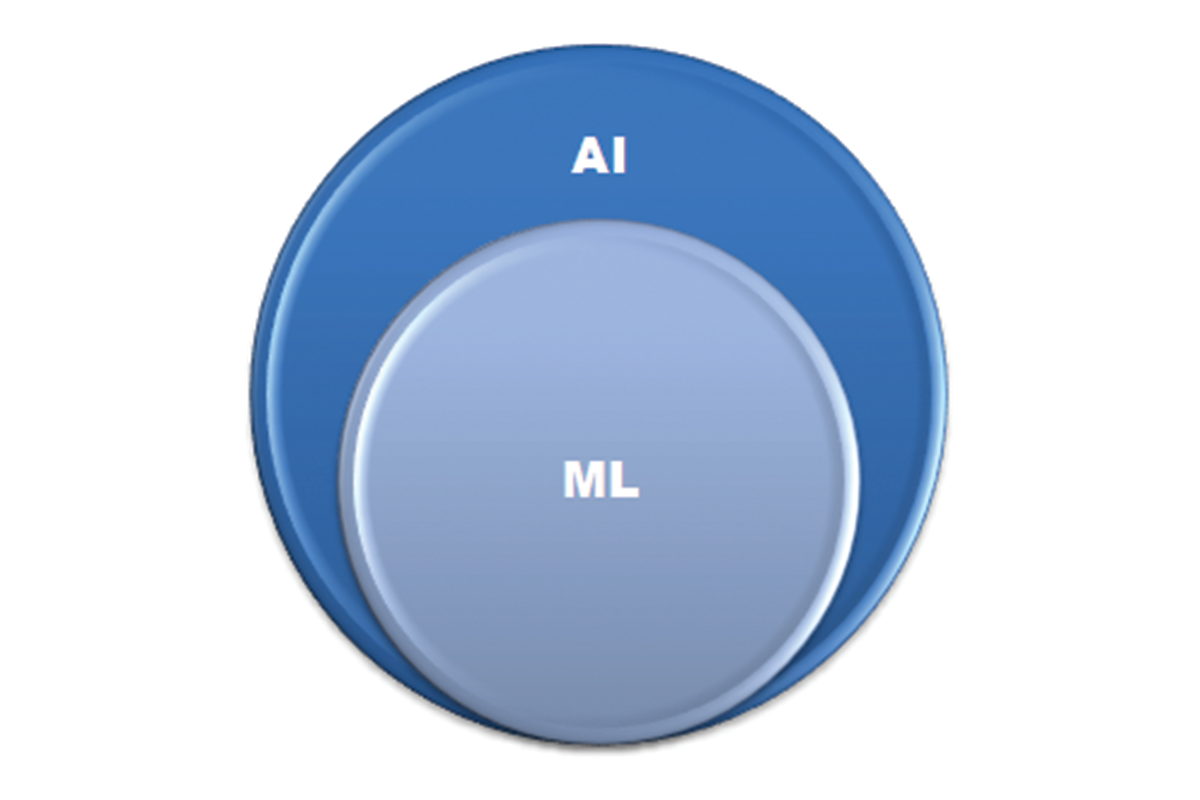
AI has other subsets such as deep learning, natural language processing (NLP), speech recognition, and robotics. This post, however, zooms in on ML alone, so we are not going to delve deeper into the other subsets.
Two Types of Machine Learning
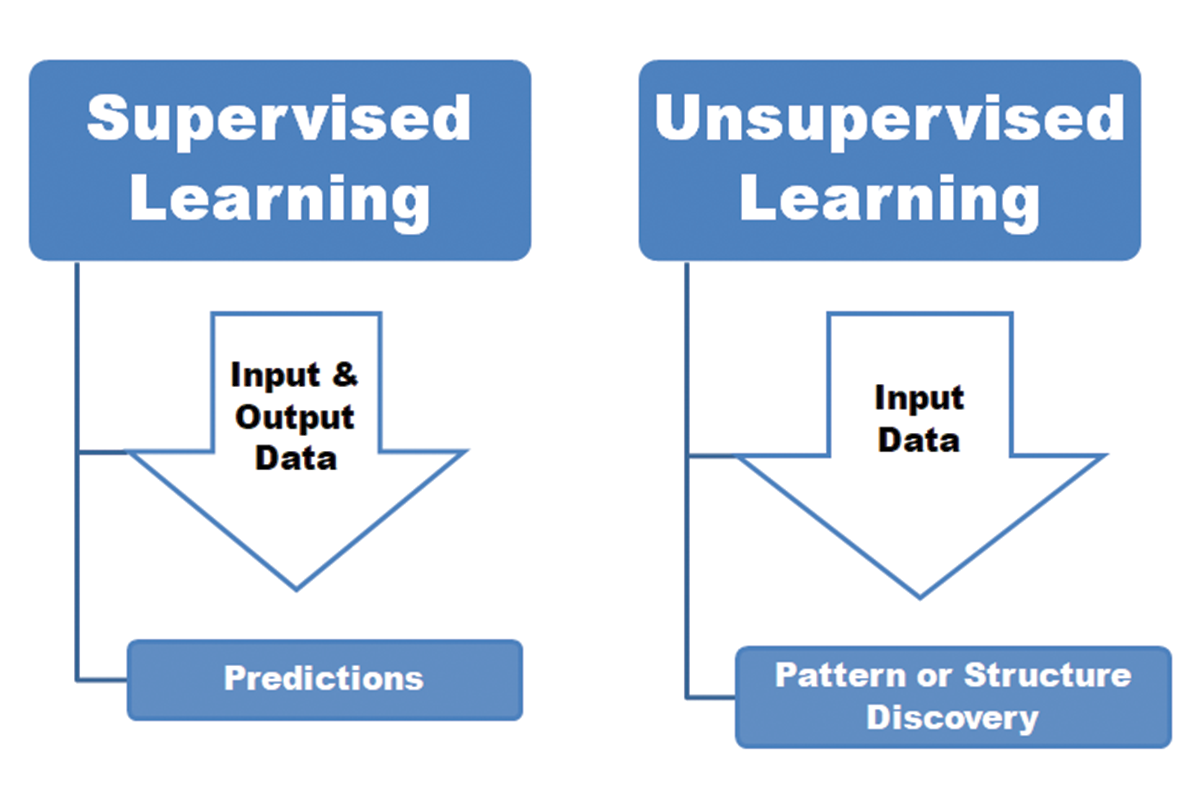
Two techniques are used in ML—supervised learning and unsupervised learning.
Supervised Learning
In supervised learning, machines get trained to predict the outcomes of unforeseen data based on information that is already labelled. Supervised learning helps solve a wide variety of real-world computation problems. For instance, a spam detection system can tag an email as spam or not, based on a model that has already labelled emails.
In the medical field, supervised learning can help predict whether a tumour is benign or malignant and whether a person will suffer a heart attack within a specified period or not, among others. The system can do that because the model looks at data from previous patients and laboratory findings.
The farming industry has also benefited from supervised learning in the form of weeding robots taught to distinguish between weeds and crops.
Supervised learning also figures in Global Positioning System (GPS)-based navigation apps such as Waze and Google Maps to predict one’s time of arrival. The system takes in necessary input data such as the time of day and weather conditions to compute how long a drive will take.
There are more real-world applications of supervised learning. Still, the common ground is that the model analyzes both input and output data, and its job is to predict or compute the output of new data.
Unsupervised Learning
Unsupervised learning trains a machine to identify underlying patterns in datasets and interpret them without labelled responses. That means that the model is left to work on its own without supervision. This technique is primarily used when there is still a need to explore the data, and you want to train the machine to look for hidden structures or patterns
Unsupervised learning is widely used in the marketing industry to identify market segments. The model gets fed with a large volume of data from a target market, which will then be grouped based on demographics, incomes, and interests.
The financial industry, which handles vast amounts of data, is also exploring unsupervised learning. Systems are being trained to consolidate, verify, and check financial data from various sources, saving financial managers the hassle of doing repetitive tasks.
Below is a figure that can better assist in differentiating supervised and unsupervised learning.
The concept of ML is not too different from the process by which humans learn. When a parent brings home a pet cat, for instance, he will need to teach the toddler that it is a cat. When the toddler goes to the park and sees a different cat, she will process the animal’s appearance (e.g., two eyes, whiskers, a tail, and so on). Based on this “data,” the child infers that the animal is a cat. That is unsupervised learning in the real world.
The parent, however, can also tell the toddler right away that it is a cat. This case shows supervised learning at work. Either way, the child learns from experience so that in her next encounter with any cat, she already knows what it is.
ML’s basis, according to some, is the model of brain cell interaction created by Donald Hebb in 1949. Today, we are still in the early stages of figuring out ML applications and self-learning software. As geoscientist Dave Waters put it, “A baby learns to crawl, walk, and then run. We are in the crawling stage when it comes to applying ML.”




















Comments